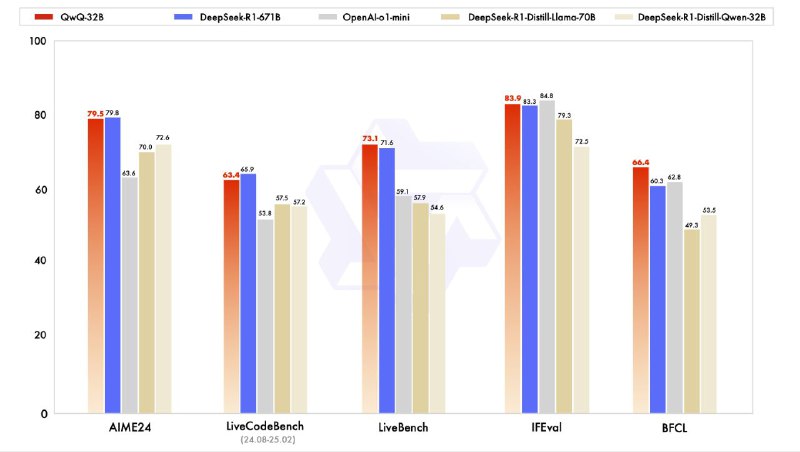
阿里通义千问团队发布QwQ-32B模型,该模型基于320亿参数,通过大规模强化学习(RL)在数学推理、编程及通用任务中展现卓越性能,与DeepSeek-R1(激活参数370亿)表现相当。训练分为两阶段:数学与编程任务RL阶段通过答案验证与代码测试反馈优化模型;通用能力RL阶段结合奖励模型与规则验证器提升综合能力,且不影响其他任务表现。模型在Hugging Face和ModelScope开源(Apache 2.0协议),支持工具调用与环境反馈自适应推理。未来计划探索更长时推理与智能体集成,推动AGI发展。
Qwen Team | Qwen Chat
Hugging Face | ModelScope
📮投稿 ☘️频道 🌸聊天 🗞️𝕏