inceptionlabs.ai 推出第一个商业规模的扩散型大语言模型 Mercury
其声称比当前LLMs快 10 倍且成本低廉的
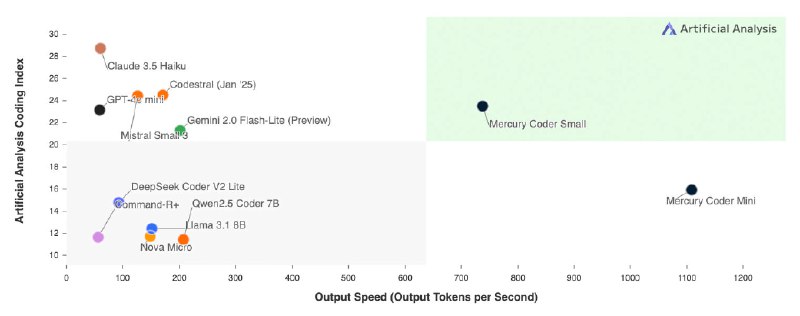
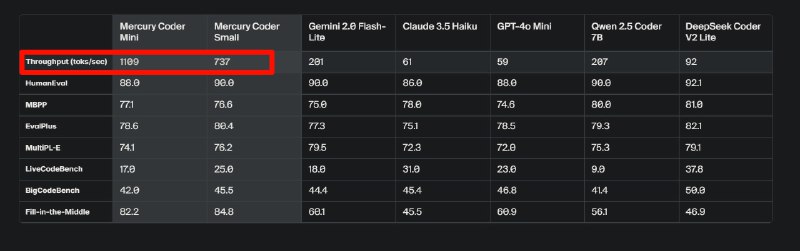
扩散型大语言模型,该模型创时代的可以型在 NVIDIA H100 上以超过 1000 个令牌/秒的速度生成响应。
与现有的代码模型相比,开发人员更喜欢 Mercury 的代码完成。在 Copilot Arena 上进行基准测试时,Mercury Coder Mini 并列第二,超过了 GPT-4o Mini 和 Gemini-1.5-Flash 等速度优化模型的性能,甚至超过了 GPT-4o 等更大的模型。同时,它是最快的型号,比 GPT-4o Mini 快约 4 倍。
免费体验|模型发布页注:什么是扩散模型LLM?
📮投稿 ☘️频道 🌸聊天 🗞️𝕏